Improving Speech Intelligibility Using Psychoacoustic Noise Reduction
Overview
- 2 Clear Speech and Noisy Signals
- 3 Conventional Noise Reduction
- 4 Two Stage Noise Reduction using Psychoacoustic Model
- 5 Comparison
Download the thesis (in german): thesis.
Clear Speech and Noisy Signals
Conventional noise reduction algorithms suffer from the very poor quality of the estimation of the noise component especially for frequency components with low signal-to-noise ratio. Mostly theses frequency are located in the upper part of the frequency scale containing human voice, i.e > 4kHz. The energy of the voice of a human is unevenly distributed along the spectrum. The main part of the energy (90% and more) occurs in the lower band of the spectrum (80Hz to 4kHz). Thus the signal-to-noise ratios for the upper band are rather low, which easily stands to reason considering white noise, whose energy distribution is homogenous distributed over the whole frequency scale. The effect of erroneous estimations of the noise component yields the so called 'musical noise', which are isolated peaks in the spectrum. Each peak represents a sinusoidal tone being perceived as a very unpleasant sound.
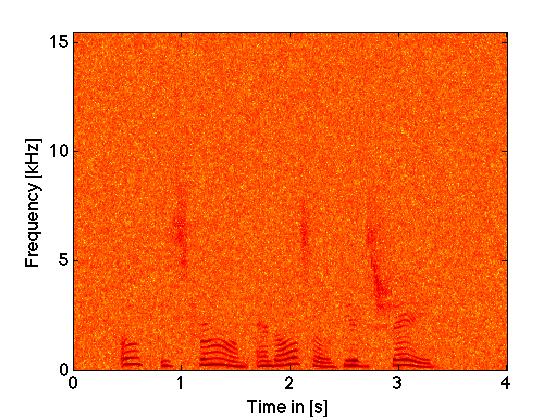 |
 |
|
jackhammer noise |
||
Conventional Noise Reduction
Wiener Filter
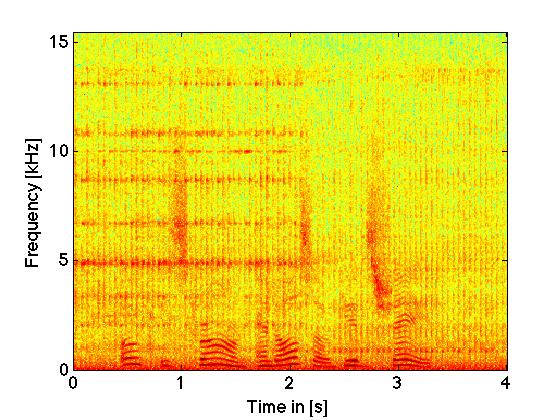
 |
 |
using wiener filter |
using wiener filter |
Two Stage Noise Reduction w/ Psychoacoustic Model
Threshold of Hearing Based Filter Rule
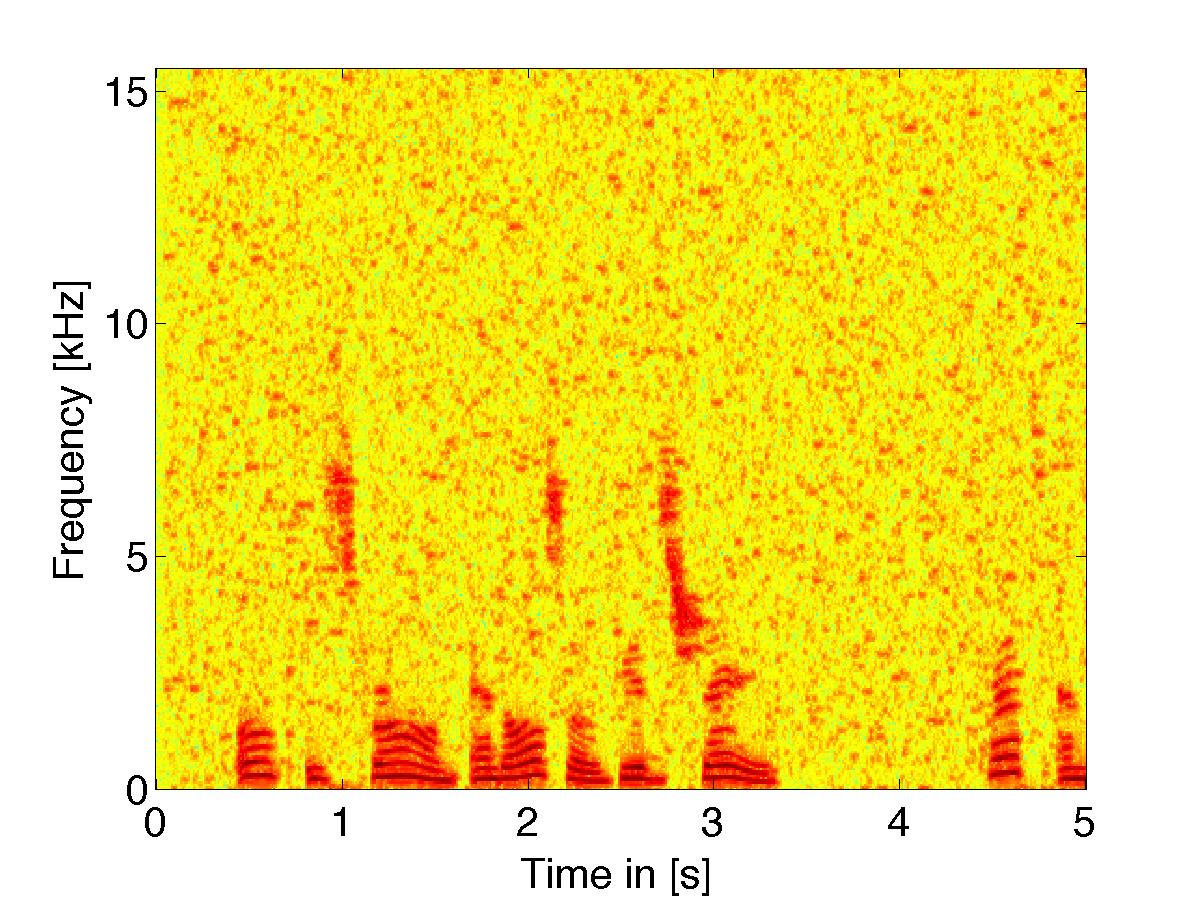
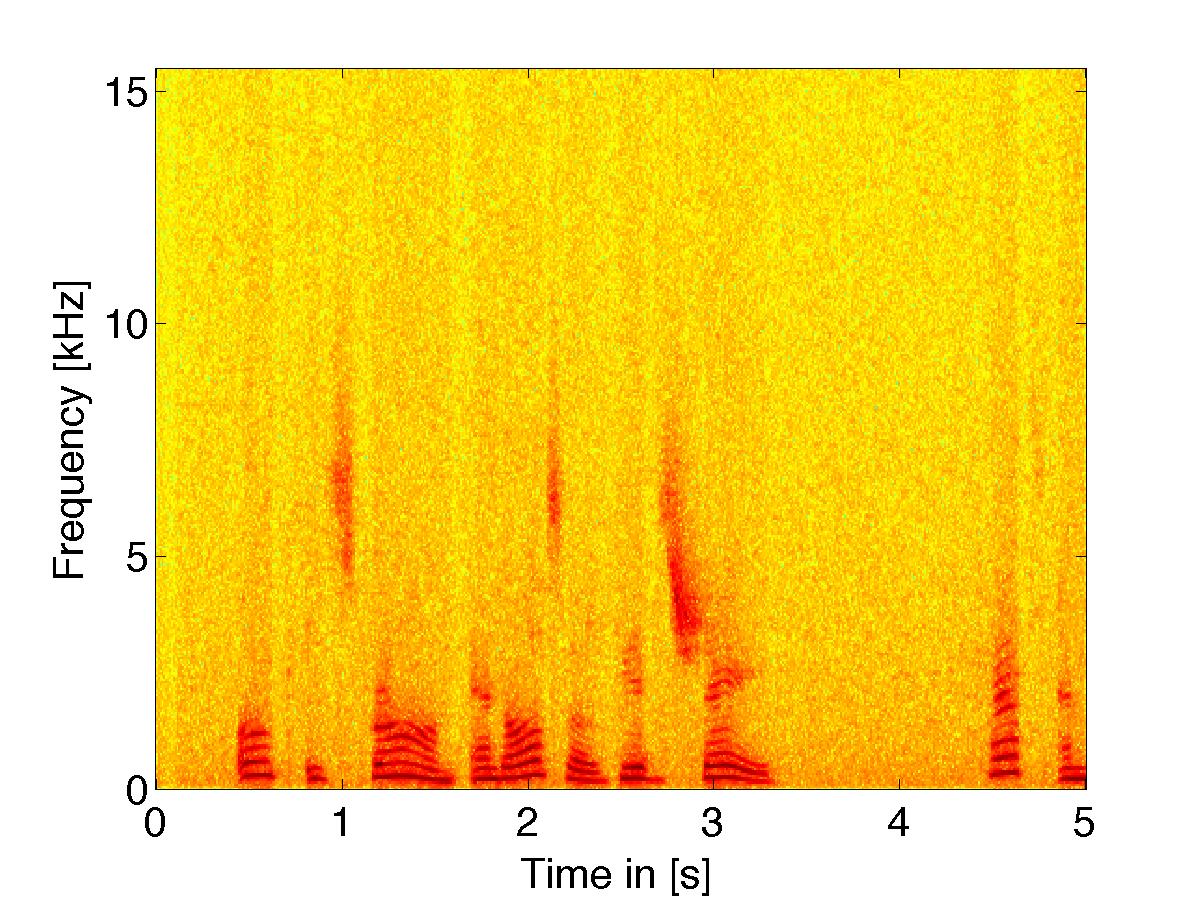 |
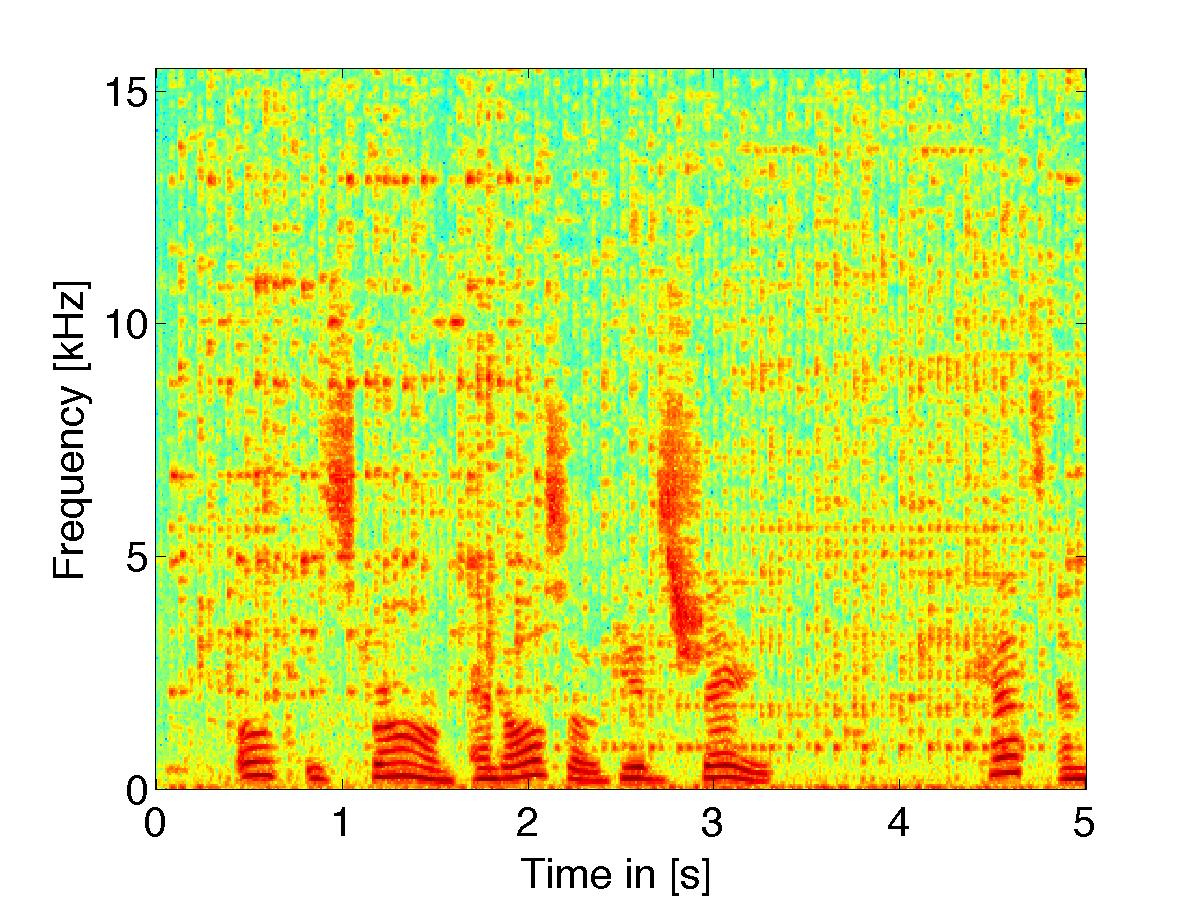
 |
(noisy signal w/ white noise) using threshold based filter weights |
(noisy signal w/ white noise) using threshold based filter weights |
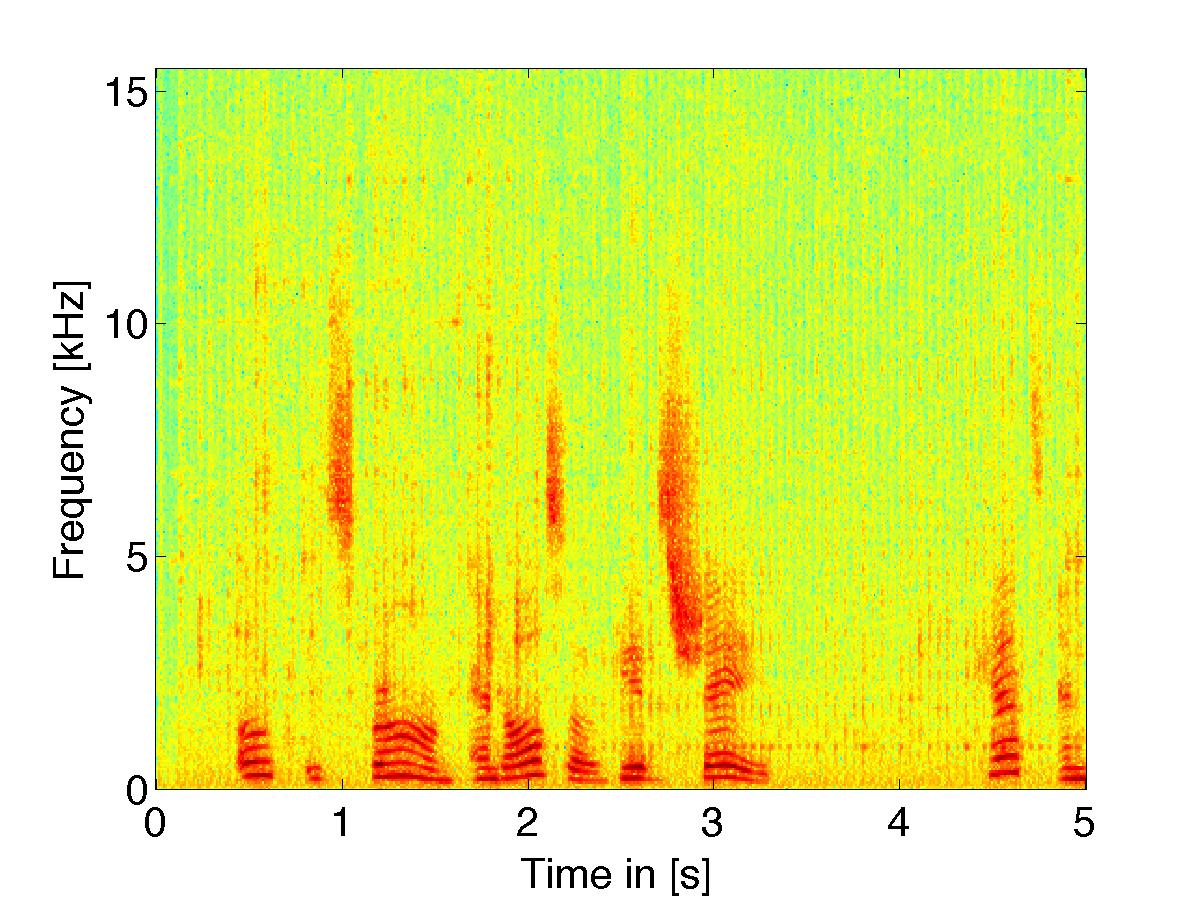
Excitation Based Filter Rule
| |
 |
(noisy signal w/ white noise) using excitation based filter weights |
(noisy signal w/ white noise) using excitation based filter weights |
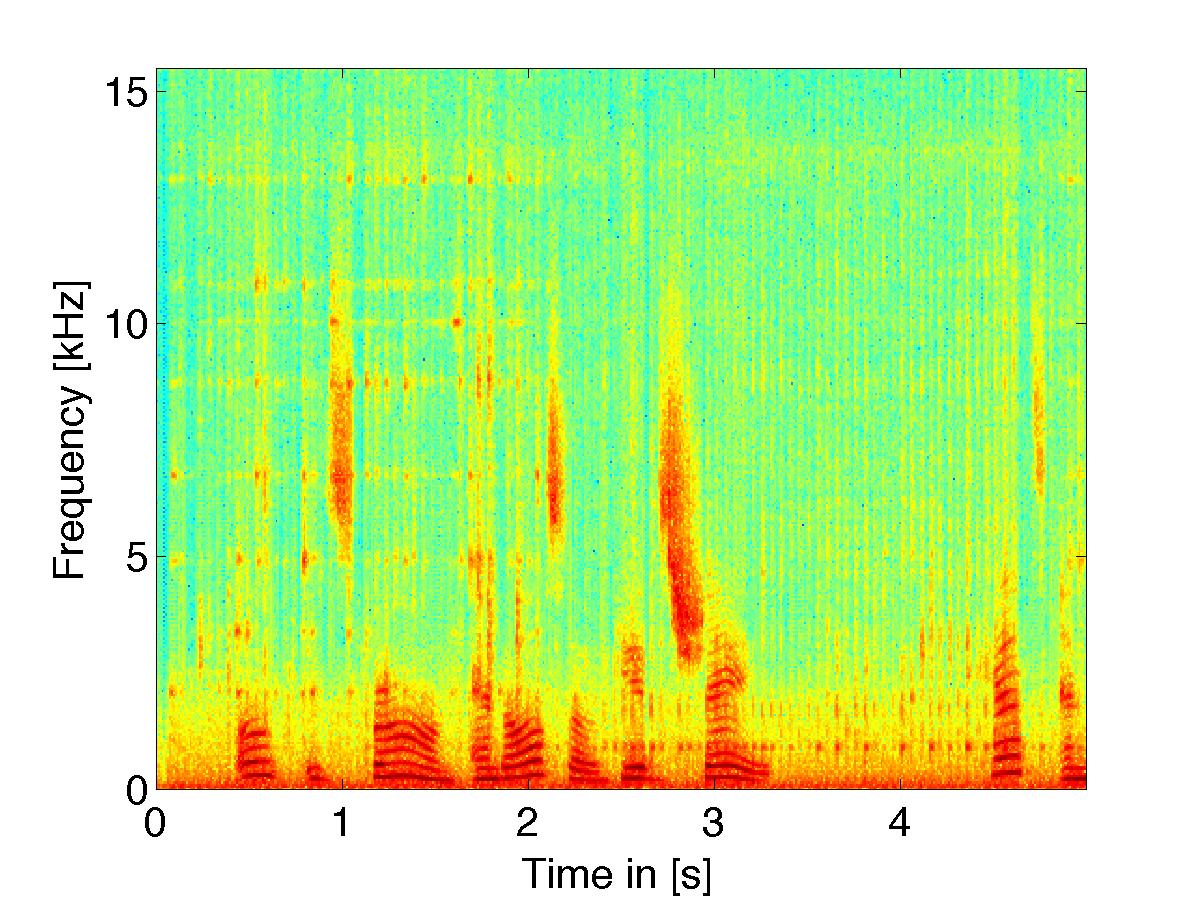
Loudness Based Filter Rule
 |
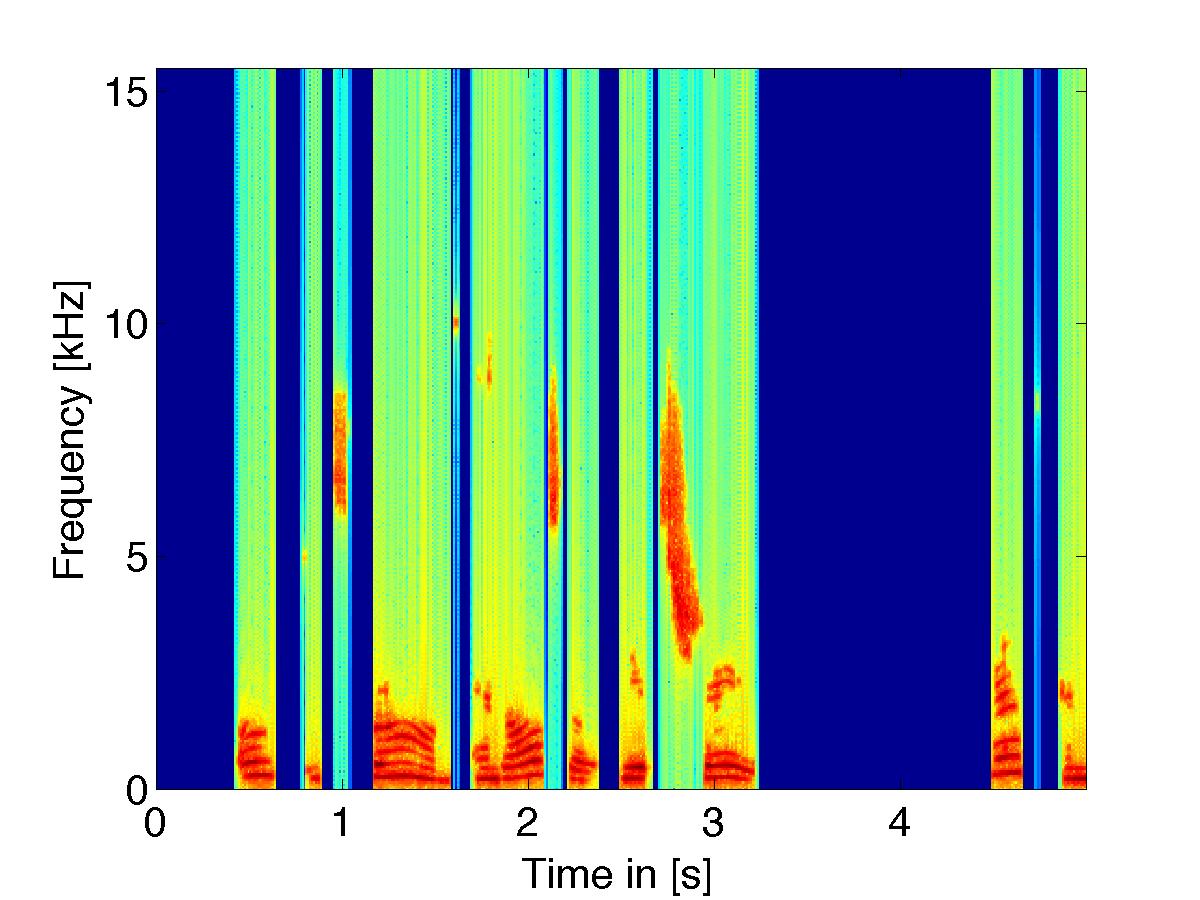 |
(noisy signal w/ white noise) using loudness based filter weights |
(noisy signal w/ white noise) using loudness based filter weights |
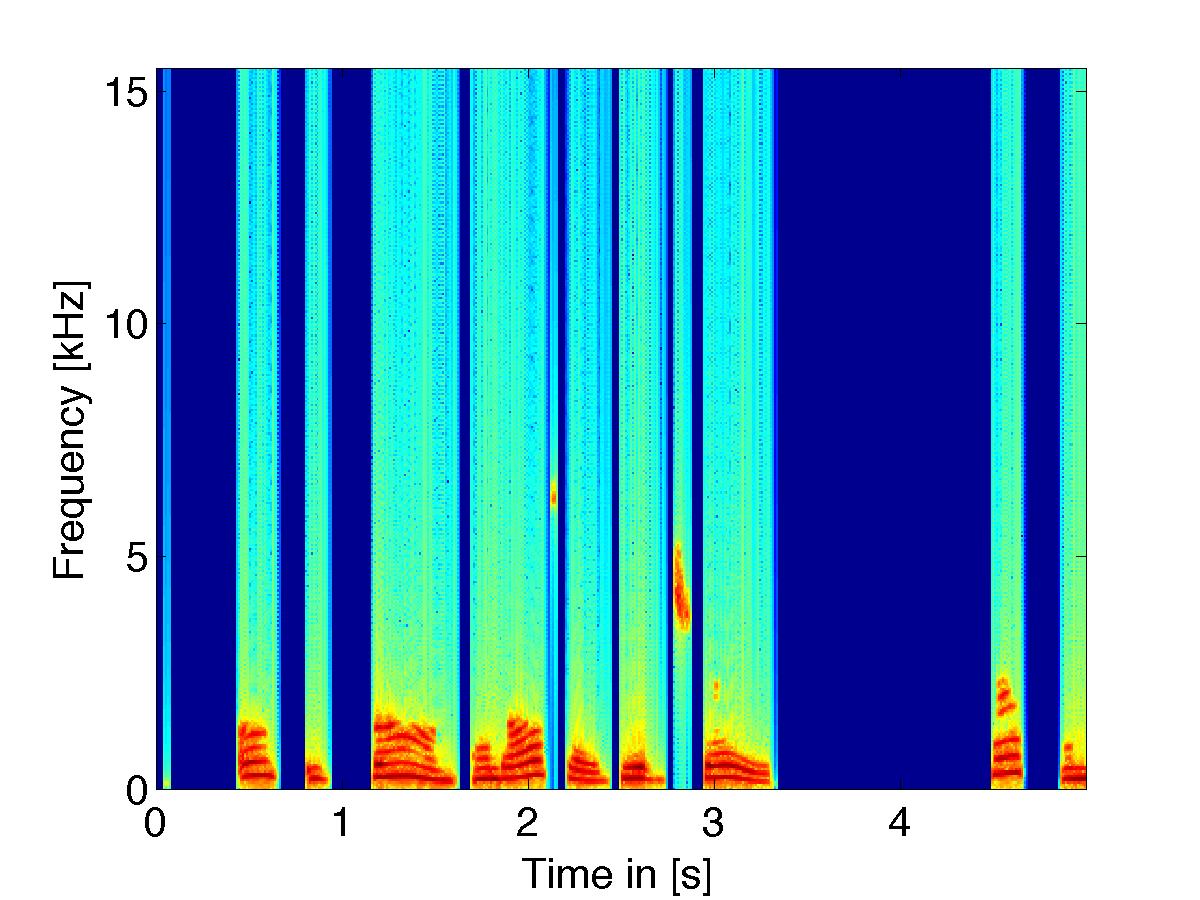
Noise Reduction w/ Combined Loudness and Excitation Based Filtering
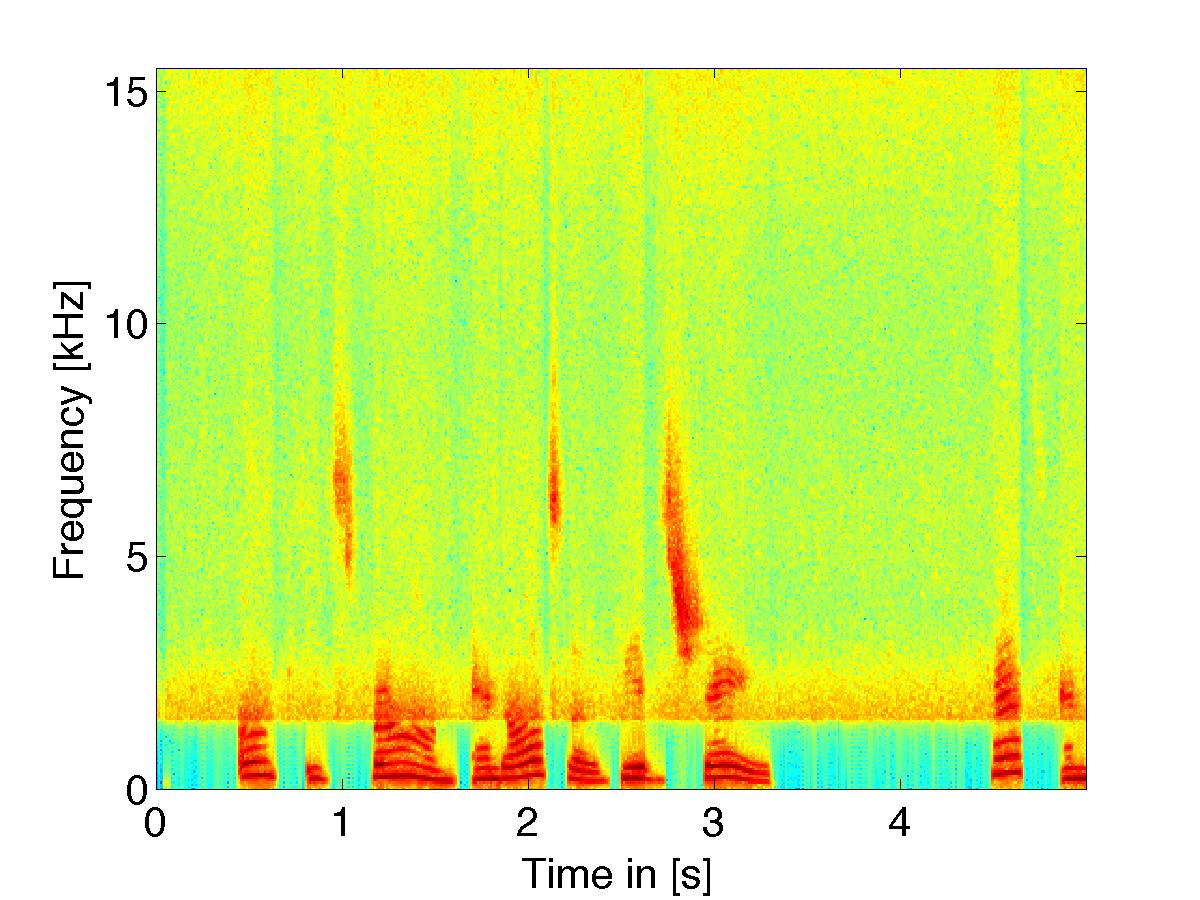 |
|
(noisy signal w/ white noise) using two combined psychoacoustic filter weights |
(noisy signal w/ white noise) using two combined psychoacoustic filter weights |
Comparison
Perceptive Speech Quality vs. Perceptive Grade of Speech Distortions
| Wiener Filter | Combined Filter Rule | |
|---|---|---|
| Perceivable Musical Noise |
- - | ++ |
| Perceptive Speech Quality |
++ | - - damped high frequency components > 8kHz ➝ muffled sound |